Welche Themen werden im Bundestag besprochen? Und wie positionieren sich die einzelnen Abgeordneten dazu? Die Prozesse und Debatten im deutschen Bundestag sind für Bürger/innen, aber auch Journalist/innen, politische Organisationen und Initiativen oft nur schwer zu überblicken. Daher haben wir uns gemeinsam mit unserem Kooperationspartner abgeordnetenwatch.de im Vorfeld zur Bundestagswahl 2017 die Plenarprotokolle des Bundestages aus der 18. Legislaturperiode (2013-2017) genauer angesehen.
In dieser Lernsektion zeigen wir euch anhand unserer Erkenntnisse, wie man parlamentarische, qualitative Daten analysieren und visualisieren kann - und wo es Probleme gibt. Dabei arbeiten wir mit unserer Methode, der Data Pipeline, mit der sich datengetriebene Projekte strukturiert umsetzen lassen.

 Fragen stellen
Fragen stellen Jedes datengetriebene Projekt startet mit einer oder mehreren Fragestellungen oder Herausforderungen, die mit Hilfe der Analyse gelöst werden sollen. Dabei müssen die Fragen nicht nur möglichst konkret, sondern auch im Rahmen der eigenen Möglichkeiten und Ressourcen umsetzbar sein. Eine geeignete Frage findet sich daher häufig erst nach einem längeren Prozess von Recherchen und Überlegungen, die nach und nach konkreter werden. Ein wichtiger Faktor ist dabei auch die Datenlage.
Anlass für die Zusammenarbeit mit Abgeordnetenwatch war die im Herbst 2017 anstehende Bundestagswahl. Gemeinsam wollten wir ein Projekt ins Leben rufen, dass Bürger/innen dabei hilft, informiertere Wahlentscheidungen zu treffen. Tools und Programme, die dieses Ziel ebenso verfolgen, gab es bereits viele (z. B. Wahl-o-Mat, DeinWal.de, Digital-o-Mat). Daher waren wir auf der Suche nach einer neuen Idee. Nach zahlreichen Brainstormings, in denen uns auch die HAW Hamburg viele Tipps und wertvollen Input lieferte, entstand die Idee, eine Art Medientracker zu bauen, der verschiedenste Zeitungsartikel und Berichterstattungen online durchsucht, die Thesen und Argumente der Parteien herausfiltert und übersichtlich darstellt. Genauere Recherchen zu den Daten und der benötigten technischen Infrastruktur zeigten aber schnell, dass dieses Vorhaben mit unseren vorhandenen zeitlichen und personellen Ressourcen nicht realisierbar war. Umdenken war noch einmal angesagt - ein wichtiges Learning, das zeigt: Die Data Pipeline ist kein linearer Prozess, sondern gibt nur die Richtung vor. Oft ist es nötig, noch einmal einen oder zwei Schritte zurückzugehen und das Projekt und das Ziel neu zu überdenken.
Durch einen Hinweis aus unserer Community kamen wir schließlich auf OffenesParlament.de. Die Plattform existiert bereits seit 2013 und ist ein Community-Projekt, zu dem viele ehrenamtlich Engagierte beigetragen haben. Wir beschlossen, der Plattform neues Leben einzuhauchen und uns dazu einmal die Plenarprotokolle des Bundestags genauer anzusehen. Wir wollten wissen: Über welche Themen wird im Bundestag gesprochen? Und welche Themen werden dabei am häufigsten verhandelt? Welche Positionen nehmen die einzelnen Abgeordneten dabei ein? Und wer spricht eigentlich am meisten? Unser neues Ziel: Regierungshandeln für alle verständlicher und transparenter zu machen.
Daten finden & bekommen Die erste Suche nach Daten beginnt häufig online mit einer Suchanfrage in Google und Co. Um hierbei spezifische Ergebnisse zu erhalten ist es jedoch wichtig, Suchmaschinen richtig zu nutzen und Suchoperatoren zu verwenden. In unserem Material findest du eine Anleitung und einige hilfreiche Tricks, um Suchmaschinen gezielter zu verwenden.
Bei der Recherche können auch Datenportale im Internet sehr hilfreich sein. Neben behördlichen Plattformen wie Destatis (Statistisches Bundesamt) oder Eurostat (Europäische Kommission) gibt es auch einige zivilgesellschaftliche Plattformen, die offene Daten bereitstellen. Eine Übersicht zu wichtigen Open Data-Portalen findest du in dieser Übersicht:
Staatliche Informationen werden häufig in PDF-Formaten veröffentlicht. Das macht die Daten häufig leserlich, gleichzeitig erschwert es Programmen wie Libreoffice und Excel die Informationen strukturiert zu verarbeiten. Um Tabellen aus PDFs zu befreien, gibt es eine Reihe an Programmen, die PDF-Informationen in maschinenlesbare Formate (z. B. json, csv) umwandeln können. Eine Open Source-Lösung hierfür ist das Tool Tabula. Mit Tabula können PDF-Tabellen markiert, überprüft und umgewandelt werden. In unserem Lernmaterial erfährst du, wie Tabula funktioniert.
Die richtigen Daten zu finden, kann manchmal äußerst schwierig und frustrierend sein, denn nicht alle Informationen sind frei verfügbar oder aber die Daten fehlen komplett. In diesen Fällen hilft leider nur hartnäckig zu bleiben und weiter nachzufragen, Daten selbst zu erheben (wenn möglich) oder die Fragestellung noch einmal anzupassen: Gibt es vielleicht Informationen zu einzelnen oder anderen Aspekten meiner Frage? Wo gibt es noch Daten in dem Bereich, der mich interessiert?
Bei unserer Recherche haben wir verschiedene Datenquellen gesammelt und dann definiert, welche Daten zuverlässig und aussagekräftig sind (Qualität der Daten), um unsere Fragen zu beantworten. Bei OffenesParlament haben wir überwiegend die historischen Daten des Bundestags zur 18. Wahlperiode (Oktober 2013 - Juni 2017) verwendet. Die Plenarprotokolle werden nach jeder Sitzung online als txt- und pdf-Dateien auf der Webseite des Bundestags veröffentlicht. Sie umfassen unter anderem Redebeiträge und Listen der Abgeordneten, Berichte und Debatten, Sitzungsverläufe und Tagesordnungspunkte, Gesetzentwürfe und Drucksachen. Da die Informationen weder als offene Daten zur Verfügung standen noch in einem maschinenlesbaren Format, haben wir die Texte zunächst mit unserem PLPR-Scraper in eine tabellarische Form übersetzt.
Zusätzlich nutzten wir Informationen zu den Profilen der einzelnen Abgeordneten von abgeordnetenwatch.de und dem Bundestag: Beruf, Geschlecht, Alter und Bilder der Abgeordneten.
Weitere spannende Datenquellen für politische Informationen sind z. B.:
 Daten säubern
Daten säubern Daten müssen vor der eigentlichen Analyse überprüft, validiert und gesäubert werden, bevor Rückschlüsse aus ihnen gezogen werden können. Bei der Säuberung der Daten werden z. B. Informationslücken recherchiert und Daten in eine strukturierte Form gebracht, damit sie von Maschinen verarbeitet werden können. Außerdem müssen die verschiedenen Datenquellen miteinander verknüpft werden, sodass ein einheitlicher Datensatz entsteht. Wenn Daten, z. B. in Excel oder Google Sheets zu übertragen sind, gibt unser Lernmaterial Hilfestellung und hält außerdem einige wichtige Tipps zur Säuberung von Daten bereit.
{“Ein weiteres Tool, mit dem sich Daten gut und schnell säubern lassen ist die Open Source-Anwendung Open Refine. Auch hier kannst du in unserem Lernmaterial nach Anleitungen und Tipps stöbern”=>nil}
Die Parlamentsdaten aus den Plenarprotokollen waren qualitative Daten - das heißt sie lagen in Textform vor. Um einzelnen Abgeordneten Redebeiträge zuordnen zu können, brachten wir die Texte mit unserem PLPR-Scraper zunächst in eine tabellarische Form. Einzelne Redebeiträge ordneten wir anschließend den Tagesordnungspunkten zu. Die Details der Tagesordnungspunkte stammten aus den Sitzungsverläufen. Die Verknüpfung mit den Redebeiträgen erstellten wir anhand der Redner/innenlisten der Plenarprotokolle. Tagesordnungspunkte verknüpften wir dann mit Informationen zu den Abgeordneten über den MdB-Merger.
Um die Themen der Plenarprotokolle herauszuarbeiten, haben wir jeden Titel der Tagesordnungspunkte klassifiziert. Die Klassifizierung erfolgte mit dem Open Source-Tool crowdcrafting. Die Liste der Arbeitsbereiche des Bundestags diente uns dabei als Grundlage und beinhaltete 18 Themen, die bei der Zuordnung der Tagesordnungspunkte bei OffenesParlament verwendet wurden.
Die Daten wurden bei der Säuberung von uns nicht inhaltlich verändert, sondern lediglich in einer anderen Form dargestellt. Um unsere Arbeitsschritte nachvollziehbar zu machen, stellten wir auf die von uns bearbeiteten Daten und Rohdaten der ursprünglichen Quellen auf OffenesParlament frei zur Verfügung.
 Daten analysieren
Daten analysieren Sobald die Daten gesäubert vorliegen, kann die Analyse starten. Auch hierfür gibt es verschiedene Tools, einfache Analysen sind aber bereits in Excel mit Hilfe von Pivot-Tabellen möglich. Mit diesen Tabellen lassen sich Zusammenhänge in den Daten, Muster, Trends und gegebenenfalls auch Ausreißer entdecken. Einige Hinweise wie man bei der Datenanalyse vorgehen kann findest du hier:
Die von uns aufbereiteten Parlamentsdaten sammelten wir in einer Datenbank, die uns erlaubt, die verknüpften Daten flexibel abzufragen. Um ein Gefühl für die Daten zu bekommen, haben wir explorativ gearbeitet und die Test-Ergebnisse in Python Notebooks festgehalten.
Außerdem haben wir von uns erstellte CSV-Dateien mit dem Open Source-Tool Orange analysiert. Orange ist ein interaktives Datamining Tool, um Teile von Datensätzen einfach zu analysieren.
Analysiert haben wir nicht nur, welche Abgeordneten in der 18. Wahlperiode am häufigsten gesprochen haben (Volker Beck, Bündnis 90/die Grünen, mit 137 Reden) und welche Themen zwischen 2013 und 2017 besonders stark debattiert wurden (am häufigsten Gesellschaftspolitik mit 252 Stunden), sondern auch wie Alters- und Geschlechtsverteilung und beruflichen Hintergründe der Sprecher/innen je nach Thema aussahen und welche Bundesländer dabei am häufigsten am Redner/innenpult standen. Im Fokus unserer Analyse standen auch besonders stark diskutierte gesellschaftspolitische Themen wie die griechische Schuldenkrise, der VW-Abgasskandal und die Ehe für alle.
 Daten visualisieren
Daten visualisieren Die neu gewonnenen Informationen können nun noch grafisch aufbereitet werden. Dies ist wichtig, da gute Datenvisualisierungen im besten Fall einen leichten Zugang zur Thematik bieten und eine höhere Überzeugungskraft besitzen als Daten in einer Tabelle. Eine gute Grafik unterstreicht dabei immer die Hauptaussagen eines Textes oder einer Datenanalyse. Dazu gibt es verschiedene Tools wie z. B. infogram, Rawgraphs.io oder Datawrapper, mit denen interaktive Datenvisualisierungen online erstellt werden können. Dabei gibt es eine Vielzahl an Diagrammen, nicht jedes ist jedoch in jedem Fall gleich gut geeignet. Eine Übersicht zu allen Diagrammtypen mit ihren Vor- und Nachteilen bietet z. B. der Dataviz Catalogue. Einige Tipps für gute Datenvisualisierungen und Anleitungen für Tools haben wir in unserem Lernmaterial zusammengefasst:
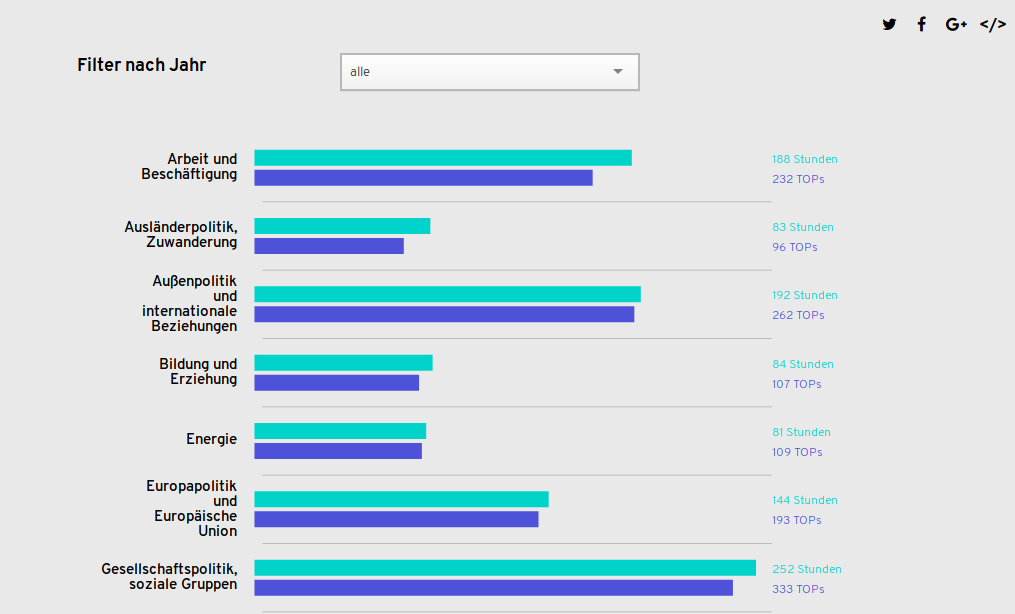
Für unsere Visualisierung haben wir die freie Bibliothek Chartist verwendet. Bei dem Großteil unserer Visualisierungen handelt es sich um interaktive Balkendiagramme, bei denen die Nutzer/innen einzelne Parameter ändern können. Einfache Diagrammtypen (wie Balken- Kreis- oder Liniendiagramme) bieten den Vorteil, dass sie einfach erschlossen werden können. Im Beispiel mit den häufigsten Themen, die in der 18. Wahlperiode besprochen wurden, stellen die Balkendiagramme die Zahl der gesprochenen Stunden (hellblau) und die Anzahl der Tagesordnungspunkte (TOPs, dunkelblau) nach dem jeweiligen Thema dar. Es kann nach der Variable Jahr gefiltert werden. So wird nicht nur ersichtlich, welche Themen am häufigsten diskutiert wurden, sondern auch wie sich die Redezeit zur Zahl der Tagesordnungspunkte verhält und wie sich dies jährlich verändert.
 Mit Daten eine Geschichte erzählen
Mit Daten eine Geschichte erzählen Die Arbeit mit den Daten endet jedoch noch nicht mit einer fertigen Visualisierung, denn diese benötigen häufig eine Erklärung und Kontextinformationen. Außerdem lassen sich mit Hilfe von Daten tolle Geschichten erzählen, die für die eigene Kampagnenarbeit effektiv genutzt werden können.
Die Möglichkeiten dazu sind vielfältig. Eine sinnvolle Leitfrage sollte sein, wie Datenvisualisierungen die Hauptaussagen einer Geschichte unterstützen können. Um schließlich Texte mit Datenvisualisierungen zu verbinden und auch interaktive Inhalte einzubetten, haben Journalist/innen des WDR gemeinsam mit Entwickler/innen das Open Source-Tool Pageflow entwickelt. Eine weiteres Tools ist Atavist. Die wichtigsten Funktionen des Tools haben wir in diesem Lernmaterial beschrieben.
Für die Präsentation unserer Parlamentsdaten haben wir uns dafür entschieden, die bereits vorhandene Webseite OffenesParlament.de mit unseren Daten anzureichern, neu zu strukturieren und aufzuarbeiten. Zum einen können hier alle 245 Plenarprotokolle der 18. Wahlperiode durchsucht und gefiltert werden, zum anderen bieten unsere Analysen zu Themen, Sprecher/innen und Hintergründen einen Einblick, was in den Protokollen für Informationen stecken und was sie über die Arbeit des Bundestages aussagen. Alle Daten sind als Open Data frei zugänglich und können von Bürger/innen, Journalist/innen und Aktivist/innen weiterverwendet werden.